CULTURE HACKER
This Decade Is About the Filter
By Lance Weiler
More than a decade ago it was “search” that was driving innovation and large investments in both infrastructure and talent. When Google first started indexing unique URLs in 1998 there were already 26 million. Two years later the amount of indexed pages had crossed the billion mark. Flash forward to this winter and the amount of unique URLs exceeds 1 trillion.
We are swimming in a sea of data. On average Americans wade through 34 gigs of information a day according to a recent report by researchers at the University of California, San Diego. The ability to “filter” this information will drive future innovation. How people are posting, commenting and clicking will greatly impact the ways films are created, curated and shared over the next decade.
The desire to tap into social data is evident in recent deals that have Google, Microsoft and Yahoo lining up to access Twitter’s feed in an effort to improve their own traditional search results. The fact that three leaders in search are interested in something as small as 140 characters of information points to the value of social streams. From breaking news instantly, in many cases before traditional outlets, the power of word of mouth threatens to devalue massive ad spends by the studios; the ability of people to connect and communicate in real time through handheld devices is challenging many established industries while at the same time enabling a new form of social curation.
Discover From Those You Follow
When I reach Maria Grineva, one of the founders of the Russian startup the Twitter Tim.es (TwitterTim.es), the company is just about to open its service to the public. The operation is a passion project by four software developers who believed that Twitter messages, also known as “tweets,” could be an excellent source of news if filtered correctly.
The Twitter Tim.es creates a custom “newspaper” based on tweets by people you follow on Twitter. The service uses an algorithm to filter messages that contain only news-related links. Results are then weighted and matched back to your interests. The more people you follow on Twitter the more interesting your personalized Twitter Tim.es newspaper will be.
What impresses me about the Twitter Tim.es is its interesting use of Twitter’s API (application programming interface). Many companies have built services to extend the functionality of Twitter — currently there are more than 50,000 registered Twitter applications. But unlike many of those developed around Twitter, the Twitter Tim.es is creating value around the people you choose to follow.
Extending APIs around social services like Twitter have a direct relationship to the discovery of films. For instance, a similar approach could be applied to the filtering of tweets related to what people are watching, the films they enjoy, the trailers they’ve sent to friends or the actors they like. This type of social curation is of particular value to independent filmmakers who have little P&A when it comes to releasing their films and who live and die by word of mouth. However in order to extend APIs and build the tools that filmmakers require there needs to be new forms of collaboration between those making films and those developing software.
The Point Where Films Find Audiences
OpenIndie is a screening on-demand service that matches audience to films. A recent example of innovation arising out of necessity, OpenIndie is a collaboration between filmmaker Arin Crumley (Four Eyed Monsters, As the Dust Settles) and software developer Kieran Masterton. The venture is not bootstrapped from traditional investors but instead raised its funding via a kickstarter.com campaign targeting other filmmakers looking for new ways to reach audiences.
Scheduled to launch in the spring, OpenIndie will enable filmmakers to list their films on its site in hopes of harnessing audience demand. Audiences will be able to discover and bookmark films they’re interested in, request a screening in their area or stage a screening of any film on the site. OpenIndie describes audiences as individuals or groups, but it also will make the service available to theaters, exhibitors and festivals. The site will attempt to build value for both filmmakers and audiences by providing a framework to measure, visualize and share the data that surrounds its participating films and the audiences who demand them.
Masterton explains, “OpenIndie believes it is beneficial to everyone for data pertaining to requests, screenings and audience attendance to be open. This is simply because the more applications that are built to utilize that data, the more attention a film gets, and the more the audience for that film grows. Whether it’s an iPhone app that tells you where you can find the nearest screening or a number-crunching Web app for market-research purposes, it’s all of value to the filmmaker and the audience.”
The same data that Masterton describes can be used to power social interactions that recommend films and connect film lovers. In an age where filmmakers are struggling to understand the digital “attention economy,” the old adage that content is king doesn’t apply. In a world where devices and people are connected like never before conversation is now king.
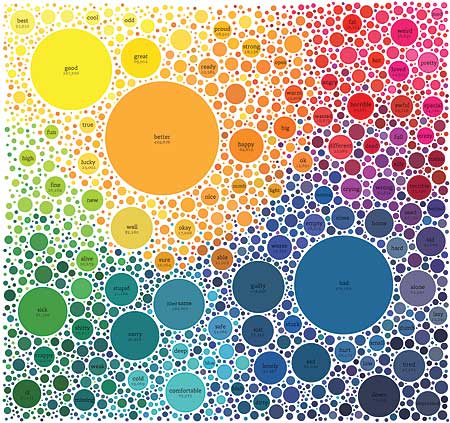
We Feel Fine
But the data surrounding conversations can also tell stories, as demonstrated by Jonathan Harris and Sep Kamvar’s project “We Feel Fine.” Started as an attempt to show what type of humanity could be found within the data that travels daily across the Web, Harris and Kamvar wrote a program that crawls blogs and Twitter every few minutes for sentences that contain the words “I feel” or “I am feeling.” By 2008 the project had captured more than 12 million emotions in a database, along with information about location, gender and age of the people feeling those emotions.
This winter they released a beautiful book entitled “We Feel Fine: An Almanac of Human Emotions” that further visualizes the data they collected. In looking through the book and having spent time on the site wefeelfine.org, I’m struck by the emotional power and the sense of story the project has. I had a chance to ask Sep Kamvar some questions about the project and in particular what type of role he sees for data and storytelling in the future. He said, “We Feel Fine is a story authored by millions of people who don’t know each other. The result is a coherent, authentic story. And this is not the only story that can be told this way — the story of love, the story of hurt, the story of helplessness. There are thousands of stories waiting to be told collaboratively by millions of people who don’t know each other. When we talk about this kind of scale, the most appropriate way to tell these stories is by building tools — tools that allow individuals to tell their personal stories in a meaningful way, and tools that collect, curate, recombine and edit these stories to form the stories of the collective. Most data analysis has focused on the macro level — statistics, trends, clusters, etc. These give important contextual information and meaningful insights, but rarely do they provoke a visceral, emotional reaction. On the other hand, many individual stories provoke an emotional reaction or social connection but lack the context that data analysis brings. For us, it’s important not only to present the high-level data analysis, but also to present the individual stories behind the statistics and allow for the user to seamlessly shift between the two.”
The Emergence Of New Models
If we take a moment to look at current trends within other industries, it’s not hard to see that creative uses of data and date filtering are at the center of emerging models. But data is sometimes seen as a foreign element to the creative process of storytelling. Therefore finding ways to apply it will benefit from experimentation.
The following are some suggestions to help get you started. If you get up and running make sure to let me know @lanceweiler.
Twitter Lists
Create a Twitter List. Ted Hope recently created a Twitter List to capture the production process from various members of the team during the production of his latest film SUPER. Side note: Ted also discovered the script for SUPER via Twitter.
Try Out A Streamreader
Streamreaders are applications that you can use to manage your various social accounts like Facebook and Twitter. TweetDeck is a popular streamreader. In fact TweetDeck recently released a special Sherlock Holmes version of their streamreader. The special version servers as a companion to an experience that was designed by AKQA and Hide & Seek entitled 221B. The two-person game was released as a promotion for Sherlock Holmes and leads players right up to the first scene of the actual film. Those playing can monitor player and character interactions within a special Sherlock Holmes edition of TweetDeck.
Create Your Own Lifestream
Lifestreams are a simple way to combine all your social activities in one place. I have one I use at lanceweiler.com. It aggregates all my feeds (music, bookmarks, blog posts, tweets) into a simple and clean listing of my online activities. Try hosted services at dipity.com or friendfeed.com and self-hosted at sweetcron.com or wordpress.org with the lifestreaming plugin.
Microblogging
Microblogging is a form of low-commitment blogging that is light on text but rich on media. I have one for all the things I find online that I like at textoflight.com. Blogs are excellent ways to collect data due to the fact that RSS feeds enable blog content to be syndicated in a variety of ways. Try posterous.com or tumblr.com.
VOD CALENDAR


 See the VOD Calendar →
See the VOD Calendar →
